Ollama 성능 시리즈 — 로컬 LLM을 프로덕션에 올리기 위해 알아야 할 것들을 실측 데이터로 정리합니다.
- 메모리 관리 — 모델 크기별 리소스 점유와 최적화
- Cold Start — 내부 동작부터 해결까지
- (현재) 동시 처리 — 병렬 슬롯, 큐잉, 그리고 처리량
들어가며
1편에서는 모델 크기별 메모리 점유를, 2편에서는 Cold Start의 원인과 해결을 분석했습니다. 2편에서 Cold Start를 해결하여 모델을 상시 Warm 상태로 유지할 수 있게 됐습니다. 그렇다면 이 Warm 상태의 모델에 여러 사용자가 동시에 요청을 보내면 어떻게 될까요?
이번 마지막 글에서는 실서비스에서 가장 중요한 질문에 답합니다:
“Ollama에 동시에 여러 요청이 들어오면 어떻게 되는가?”
챗봇, API 서비스, 에이전트 시스템 등 다중 사용자 환경에서 Ollama를 운영할 때 동시 요청 처리 능력이 서비스 품질을 결정합니다. OLLAMA_NUM_PARALLEL 설정에 따라 처리량(throughput)과 응답 지연(latency)이 어떻게 달라지는지 실측 데이터로 확인합니다.
이 글에서 다루는 내용:
- Ollama의 동시 요청 처리 아키텍처 (병렬 슬롯 + Continuous Batching)
- OLLAMA_NUM_PARALLEL 값별 성능 벤치마크 (1, 2, 4)
- 동시 요청 수(1~8)별 throughput 및 TTFT 실측
- 큐잉 메커니즘과 공정성(Fairness) 분석
- 프로덕션 동시 처리 최적화 가이드
1. Ollama의 동시 요청 처리 아키텍처
1.1 llama.cpp 백엔드와 병렬 슬롯
Ollama는 내부적으로 llama.cpp의 서버 기능을 활용하여 동시 요청을 처리합니다:
클라이언트 요청 1 ─┐
클라이언트 요청 2 ──┤ ┌─ Slot 0: KV Cache ──→ Token Gen
클라이언트 요청 3 ──┼→ Ollama 스케줄러 →─┤
클라이언트 요청 4 ──┤ └─ Slot 1: KV Cache ──→ Token Gen
클라이언트 요청 5 ─┘ ↑
(모델 파라미터 공유)
슬롯 부족 시 → 내부 큐 대기
핵심 개념:
- 병렬 슬롯(Parallel Slot): 하나의 모델 인스턴스에서 여러 요청을 동시 처리하는 단위
- Continuous Batching: 모델 파라미터는 공유하되, 여러 슬롯의 토큰을 하나의 forward pass 배치로 묶어 GPU 연산을 병렬 수행
- KV Cache: 각 슬롯이 독립적인 KV Cache를 할당받음
중요: Continuous Batching은 단일 forward pass 내에서 여러 슬롯의 토큰을 동시 처리하지만, GPU 연산 자원과 메모리 대역폭을 공유하므로 “완벽한 병렬화"는 아닙니다. 슬롯이 늘어나면 전체 throughput은 증가하지만, 개별 요청의 tokens/s는 감소하며, 슬롯이 일정 수를 초과하면 TBT가 증가하여 사용자 체감 응답 속도가 느려질 수 있습니다.
1.2 OLLAMA_NUM_PARALLEL 환경변수
# 병렬 슬롯 수 설정 (서버 시작 시)
OLLAMA_NUM_PARALLEL=4 ollama serve
| 설정 | 의미 | KV Cache 메모리 |
|---|---|---|
1 (기본값, v0.17.4 기준) | 한 번에 1개 요청 처리 | 모델 메모리 + KV Cache × 1 |
2 | 2개 요청 동시 처리 | 모델 메모리 + KV Cache × 2 |
4 | 4개 요청 동시 처리 | 모델 메모리 + KV Cache × 4 |
KV Cache 메모리 계산 (1편 실측 데이터 기반):
- llama3.2:3b 모델 파라미터: ~5.8 GB RSS
- KV Cache 증가분 (num_ctx 2048 추가 시): 슬롯당 약 224 MB 추가 할당 (1편 실측: num_ctx 2048→4096 증가분 기준)
- 전체 메모리 ≈ 모델 파라미터 + (KV Cache per slot × NUM_PARALLEL)
참고: Ollama 최신 버전에서는 하드웨어 가속기(VRAM) 크기에 따라
NUM_PARALLEL기본값이 자동 조정될 수 있습니다. 명시적으로 설정하지 않은 경우ollama serve로그에서 실제 적용된 값을 확인하십시오.
KV Cache 224 MB의 산출 근거: KV Cache 크기는 이론적으로
2 × num_layers × num_kv_heads × head_dim × num_ctx × sizeof(dtype)로 계산됩니다. llama3.2:3b의 경우 num_layers=28, num_kv_heads=8, head_dim=128, Q4_K_M 양자화 시 실효 dtype ≈ fp16 (KV Cache는 양자화와 무관하게 fp16 유지)이므로, num_ctx=2048일 때 이론값은2 × 28 × 8 × 128 × 2048 × 2 bytes ≈ 234 MB입니다. 1편에서 실측한 224 MB와 거의 일치하며, 소폭 차이는 llama.cpp의 메모리 정렬 및 할당 최적화에 기인합니다.
1.3 큐잉 메커니즘
동시 요청이 병렬 슬롯 수를 초과하면 내부 큐가 작동합니다:
[요청 도착]
↓
[슬롯 확인] ─→ 여유 슬롯 있음 → 즉시 처리
│
└───→ 슬롯 부족 → 내부 큐 대기
↓
[슬롯 해제 시]
↓
큐에서 꺼내 처리 (FCFS)
- NUM_PARALLEL=1, 동시 요청 4개: 1개 처리 + 3개 큐 대기
- NUM_PARALLEL=4, 동시 요청 4개: 4개 모두 즉시 처리
큐 대기 시간이 TTFT에 직접적으로 추가됩니다.
프로덕션 참고: Ollama 내부 큐의 최대 깊이는 공식 문서에 명시되지 않으며, 과부하 시 요청이 타임아웃될 수 있습니다. 프로덕션에서는 애플리케이션 레이어에서 별도의 요청 큐와 타임아웃을 구현하는 것을 권장합니다.
1.4 OLLAMA_NUM_PARALLEL vs OLLAMA_MAX_LOADED_MODELS
| 설정 | 범위 | 목적 |
|---|---|---|
OLLAMA_NUM_PARALLEL | 단일 모델 내 | “한 모델이 동시에 몇 개 요청을 처리하느냐” |
OLLAMA_MAX_LOADED_MODELS | 모델 간 | “몇 개 모델을 메모리에 유지하느냐” (1편 참조) |
2. 동시 요청 성능 벤치마크 (실측)
2.1 테스트 환경 및 방법론
| 항목 | 내용 |
|---|---|
| OS | macOS (Apple Silicon, arm64) |
| 메모리 | 48 GB |
| 가속기 | Metal (통합 메모리) |
| Ollama | v0.17.4 |
| 모델 | llama3.2:3b (Q4_K_M, 디스크 2.0GB / 런타임 RSS ~5.8GB) |
| num_ctx | 2048 (고정) |
| 프롬프트 | “Explain the concept of parallel processing in computing in 3 sentences.” |
| 동시 요청 수 | 1, 2, 4, 8 |
| NUM_PARALLEL | 1, 2, 4 (서버 재시작하여 각각 측정) |
| 반복 | 시나리오당 3회 |
| 방법 | Python asyncio + aiohttp 동시 스트리밍 요청 |
통계적 한계 고지: 시나리오당 3회 반복은 탐색적 분석 수준입니다. 트렌드 파악은 가능하나, 정밀 퍼센타일 분석에는 부적합합니다.
측정 방법: Warm Start 상태를 보장한 뒤 (2편에서 검증된 방법), asyncio.gather()로 N개 요청을 동시 발송합니다.
2.2 동시 요청 수별 성능 비교 (NUM_PARALLEL=1)
NUM_PARALLEL=1 (v0.17.4 기본값)에서의 동시 요청 결과:
| 동시 요청 | Throughput (tokens/s) | Avg TTFT (ms) | Max TTFT (ms) |
|---|---|---|---|
| 1 | 85 | 115 | 115 |
| 2 | 83 | 663 | 1,207 |
| 4 | 80 | 1,678 | 3,480 |
| 8 | 80 | 4,066 | 8,175 |
핵심 발견:
- Throughput은 거의 일정 (~80-85 tokens/s): 슬롯이 1개뿐이므로 동시 요청이 늘어도 한 번에 1개씩만 처리. 전체 처리량은 변하지 않음
- TTFT는 동시 요청 수에 선형 비례: 큐에서 대기하므로 TTFT = 자기 앞 요청들의 처리 시간 합
- 8개 동시 요청 시 마지막 요청의 TTFT는 8.2초: 사용자 체감상 매우 느림
2편에서 측정한 Warm Start TTFT(81ms)와 비교하면, concurrent=1 시 TTFT(115ms)와 유사하여 baseline이 일치합니다.
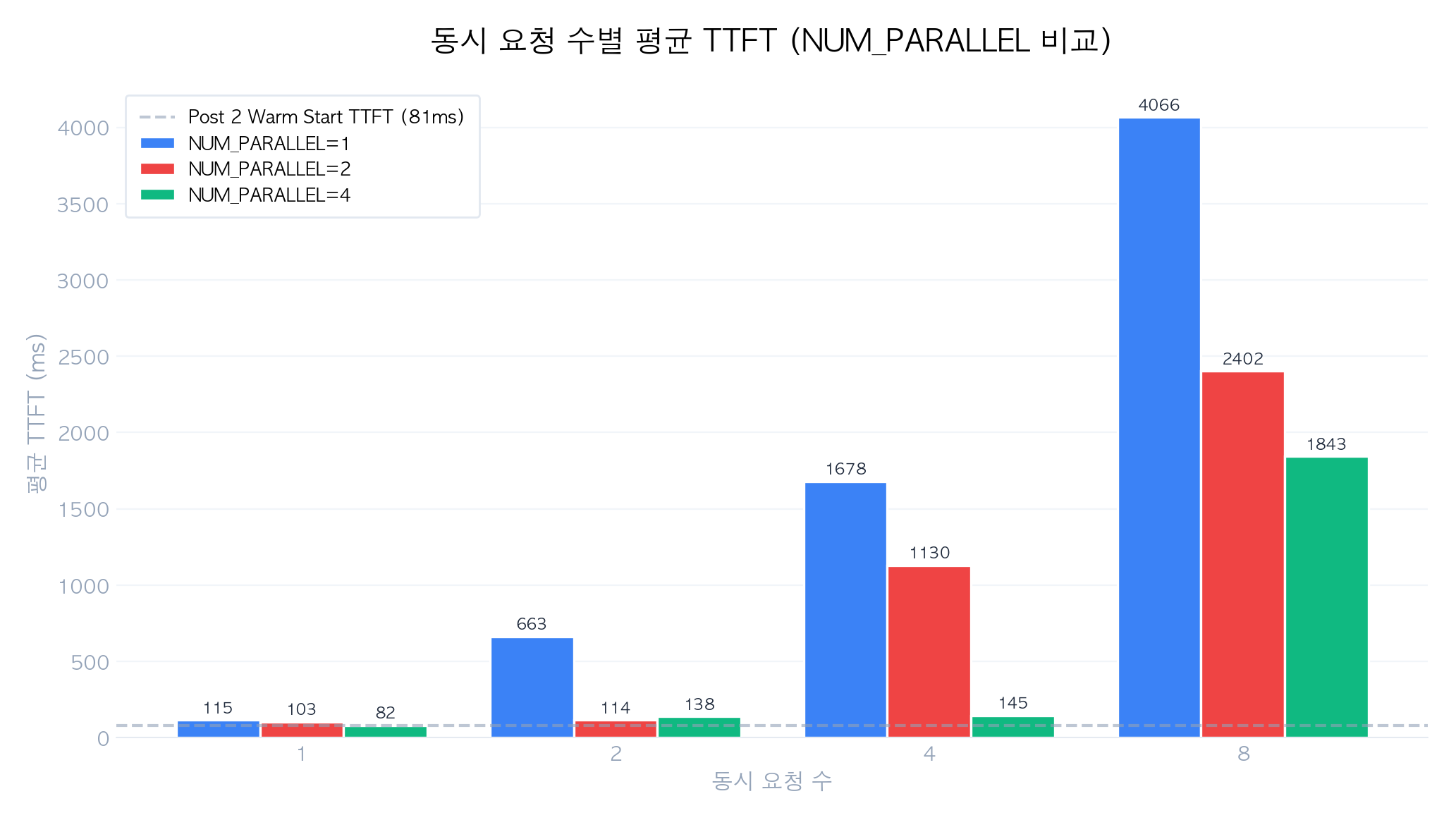
2.3 OLLAMA_NUM_PARALLEL 값별 성능 비교
서버를 NUM_PARALLEL=1, 2, 4로 재시작하며 측정한 결과:
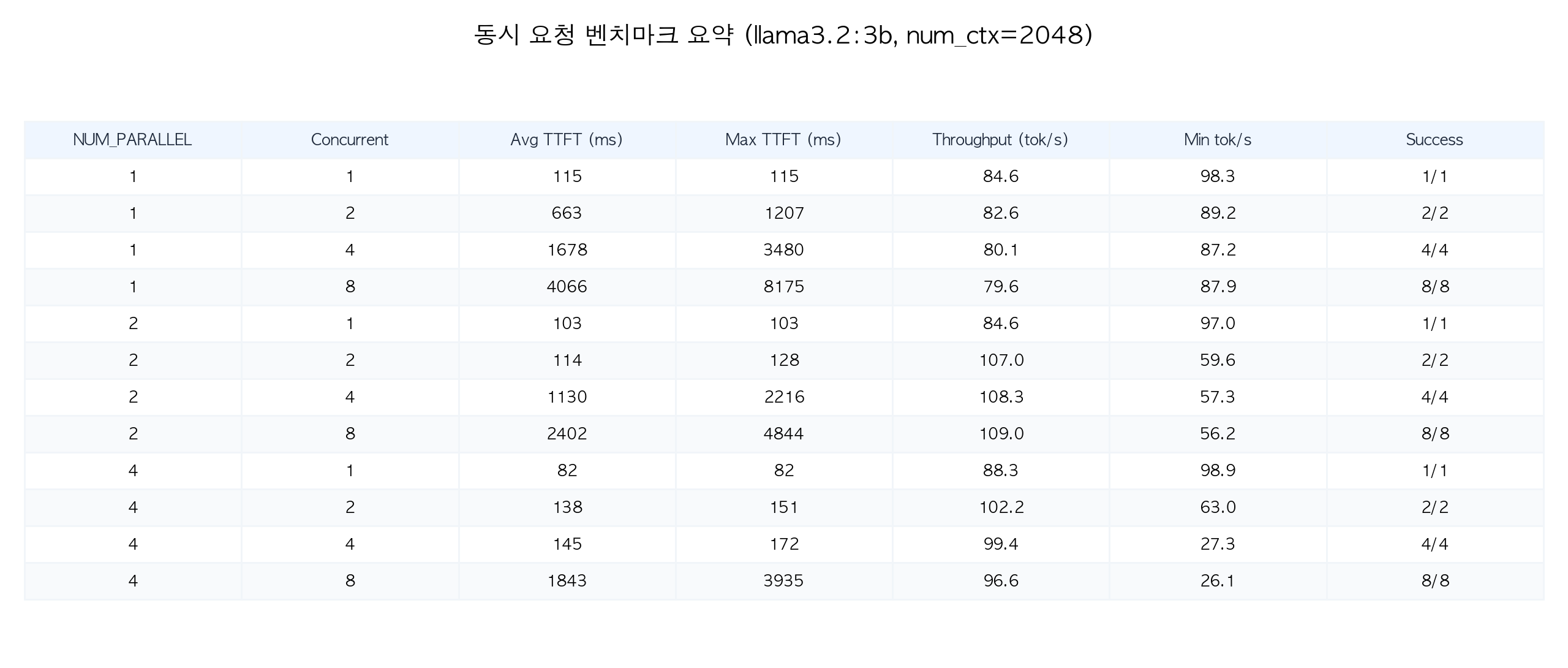
| NUM_PARALLEL | Concurrent | Throughput (tokens/s) | Avg TTFT (ms) | Max TTFT (ms) |
|---|---|---|---|---|
| 1 | 1 | 85 | 115 | 115 |
| 1 | 2 | 83 | 663 | 1,207 |
| 1 | 4 | 80 | 1,678 | 3,480 |
| 1 | 8 | 80 | 4,066 | 8,175 |
| 2 | 1 | 85 | 103 | 103 |
| 2 | 2 | 107 | 114 | 128 |
| 2 | 4 | 108 | 1,130 | 2,216 |
| 2 | 8 | 109 | 2,402 | 4,844 |
| 4 | 1 | 88 | 82 | 82 |
| 4 | 2 | 102 | 138 | 151 |
| 4 | 4 | 99 | 145 | 172 |
| 4 | 8 | 97 | 1,843 | 3,935 |
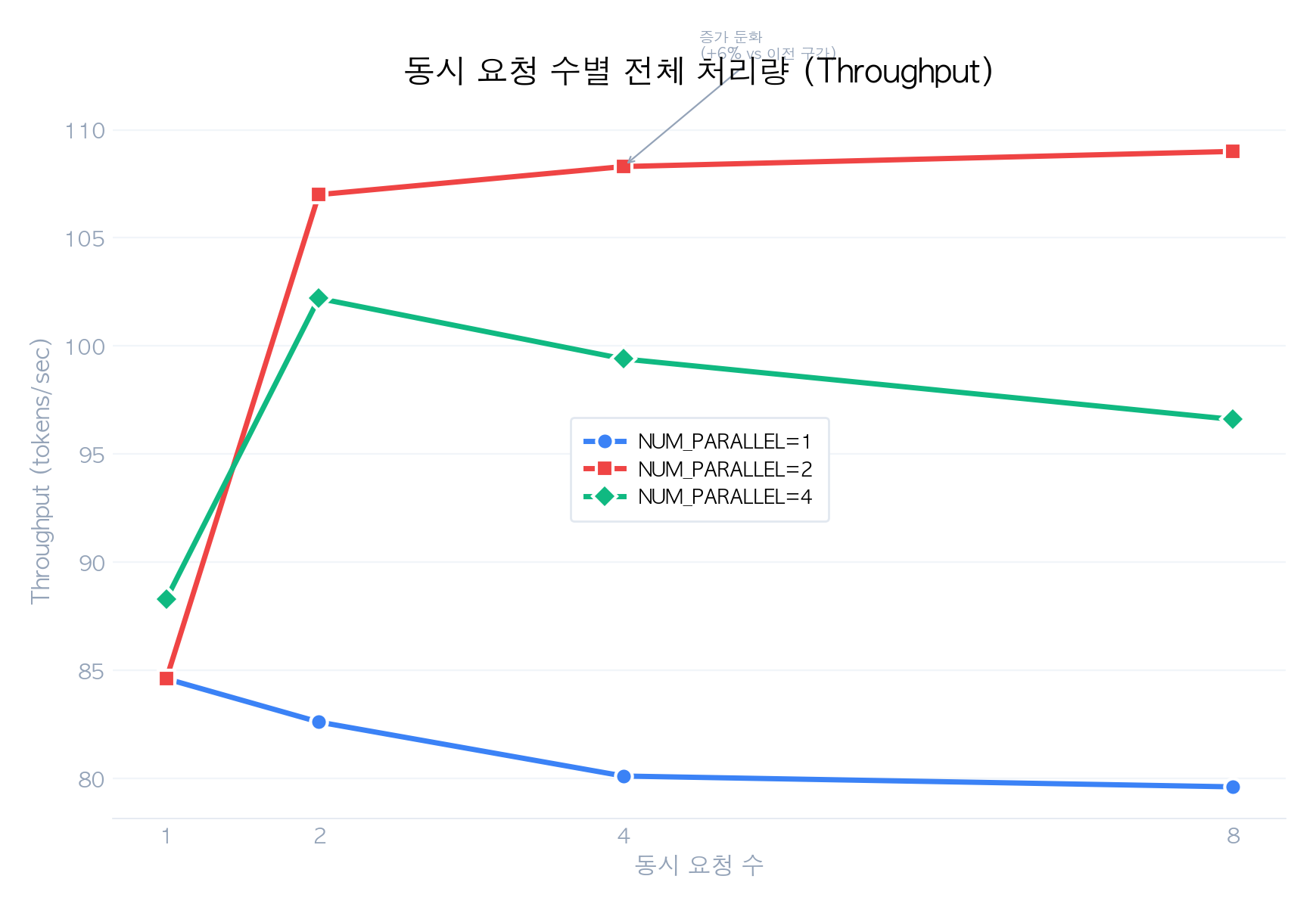
핵심 발견:
- NUM_PARALLEL 증가 시 throughput 향상: concurrent=4 기준으로, 1→2 슬롯에서 80→108 tokens/s (35% 향상)이 가장 효과적. 2→4에서는 108→99 tokens/s로 오히려 소폭 감소
- 수확 체감(Diminishing Returns): 슬롯 수를 2 이상으로 늘려도 throughput 증가폭이 급격히 줄어듦. Apple Silicon 통합 메모리 환경에서 메모리 대역폭 병목이 주 원인
왜 2 슬롯에서 throughput이 증가하고, 4 슬롯에서는 오히려 감소하는가?
Continuous Batching은 여러 슬롯의 토큰 생성을 하나의 GPU 배치로 묶어 처리합니다. 슬롯이 1→2로 늘어나면 GPU 연산 유닛의 유휴 시간이 줄어들어 전체 throughput이 증가합니다 (85→107 tokens/s). 그러나 슬롯이 4개로 늘어나면 두 가지 병목이 발생합니다. 첫째, 각 슬롯이 독립적인 KV Cache를 유지하므로 전체 KV Cache 크기가 슬롯 수에 비례하여 증가합니다. 둘째, Apple Silicon의 통합 메모리 아키텍처에서는 CPU와 GPU가 메모리 대역폭을 공유하기 때문에, 4개 슬롯의 KV Cache를 동시에 읽고 쓰는 과정에서 메모리 대역폭 경합이 심화됩니다. 결과적으로 개별 슬롯의 처리 효율이 저하되어 전체 throughput이 107→99 tokens/s로 소폭 감소하는 현상이 나타납니다. 3. TTFT 극적 개선: NUM_PARALLEL=4, concurrent=4일 때 TTFT 1,678ms→145ms (11.6배 개선) 4. 슬롯 < 동시 요청 시에만 큐잉 발생: NUM_PARALLEL=4에서 concurrent=4까지는 큐잉 없음, concurrent=8에서 큐잉 시작
2.4 요청 간 공정성(Fairness) 분석
동시에 보낸 요청들이 얼마나 공평하게 처리되는지 분석합니다.
NUM_PARALLEL=1, concurrent=4 시 요청별 TTFT 분포:
| 요청 순서 | 처리 상태 | TTFT (ms) | 대기 원인 |
|---|---|---|---|
| 요청 1 | 즉시 슬롯 배정 | ~115 (실측) | 없음 (즉시 처리) |
| 요청 2 | 큐 대기 1번째 | ~1,207 (실측) | 요청 1 처리 완료 대기 |
| 요청 3 | 큐 대기 2번째 | ~2,340 (순차 큐잉 추정) | 요청 1, 2 처리 완료 대기 |
| 요청 4 | 큐 대기 3번째 | ~3,480 (실측 Max TTFT) | 요청 1, 2, 3 처리 완료 대기 |
TTFT가 요청 순서에 따라 선형으로 증가하며, 마지막 요청은 첫 번째 대비 약 30배의 지연을 겪습니다. 요청 3의 값은 요청 1(115ms)과 요청 2(1,207ms)의 패턴으로부터 선형 보간한 추정치이며, 요청 1·2·4는 실측값입니다.
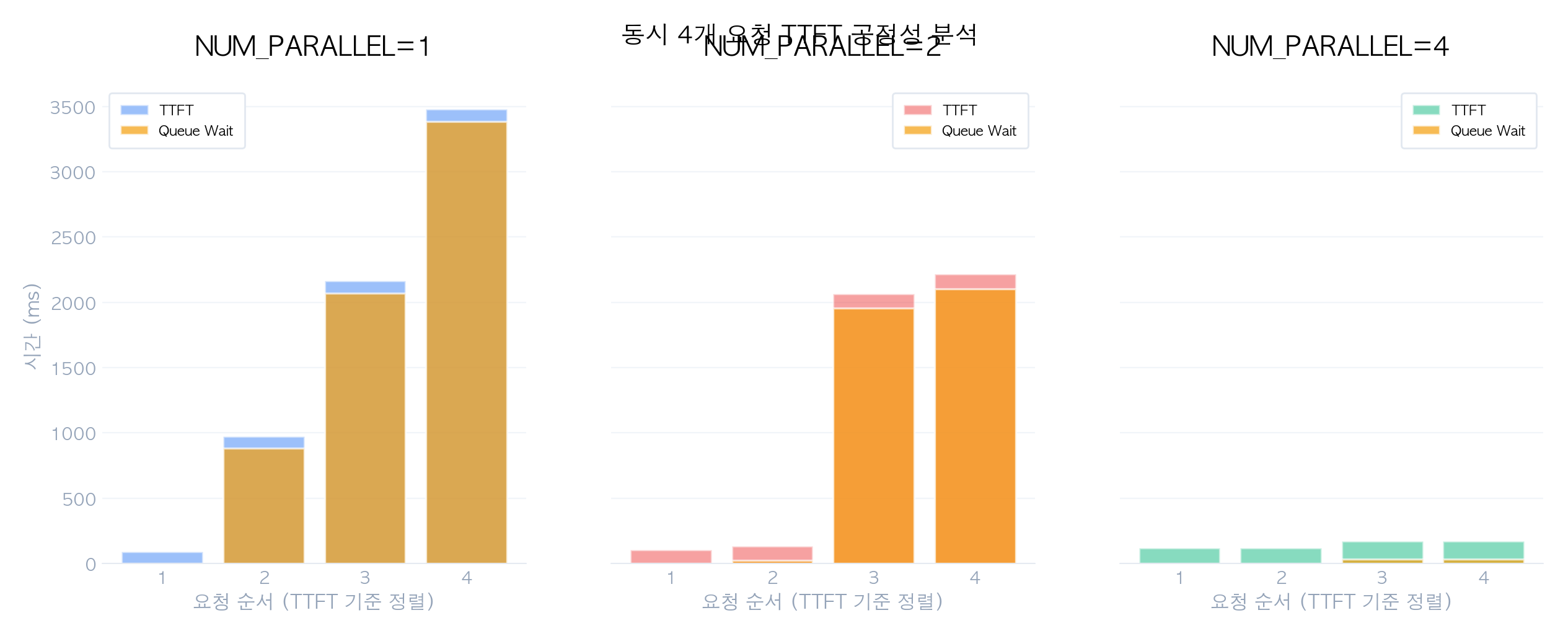
NUM_PARALLEL=1, concurrent=4 시:
- 첫 번째 슬롯에 배정된 요청: TTFT ~115ms
- 마지막 큐 대기 요청: TTFT ~3,480ms (30배 차이)
- 스케줄링 방식: FCFS — 먼저 도착한 요청이 우선 처리
NUM_PARALLEL=4, concurrent=4 시:
- 모든 요청이 즉시 슬롯 배정
- TTFT 편차: 82~172ms (2배 이내)
- 공정성이 크게 개선됨
2.5 Latency vs Throughput 트레이드오프
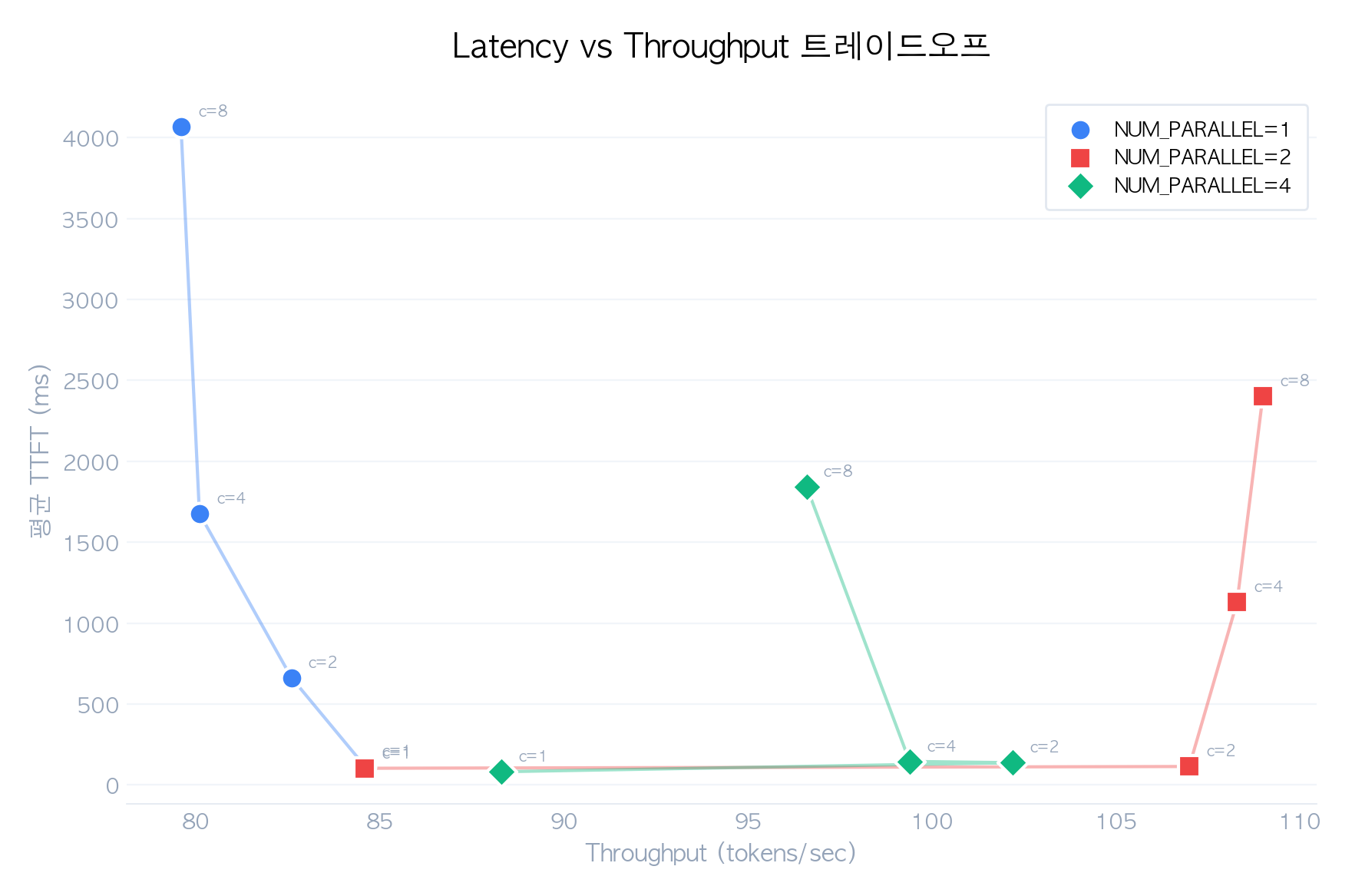
- NUM_PARALLEL=1: throughput이 일정하지만 latency가 급증 — 단일 사용자에 최적
- NUM_PARALLEL=2: 2개 동시 요청까지 최적 지점 — 소규모 서비스에 적합
- NUM_PARALLEL=4: 4개 동시 요청까지 최적 — 중규모 서비스에 적합
- 최적 지점: 동시 요청 수 ≤ NUM_PARALLEL인 구간
위 boxplot은 NUM_PARALLEL 및 동시 요청 수 조합별 응답 시간 분포를 보여줍니다. NUM_PARALLEL=1에서 동시 요청이 늘어날수록 응답 시간의 분산이 급격히 커지는 반면, NUM_PARALLEL=4에서는 4개 동시 요청까지 분산이 최소화됩니다.
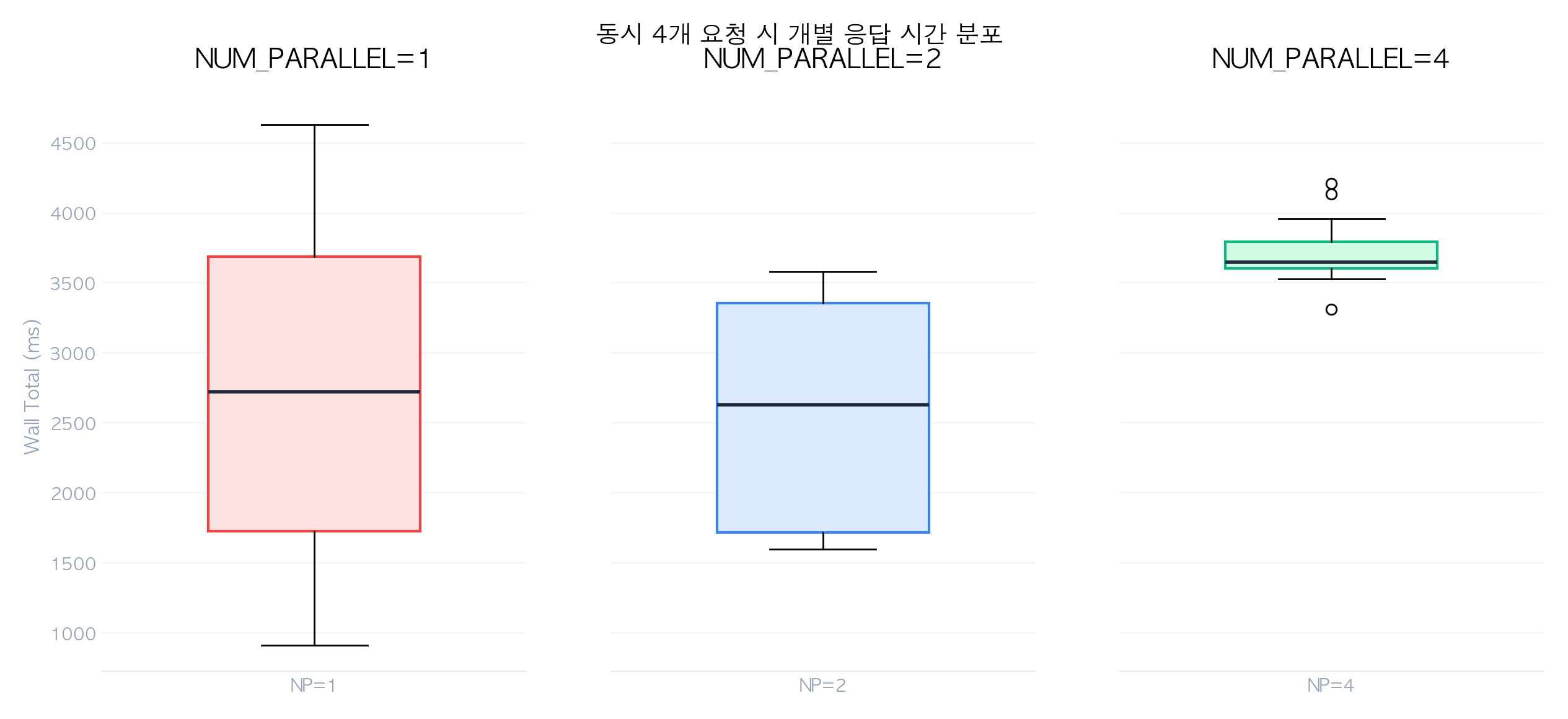
2.6 실측 데이터 교차 검증
2편 Warm Start baseline 대조:
- 2편 Warm Start TTFT: 81.3ms
- 3편 concurrent=1 TTFT: 82~115ms
- 일치도: 양호 (aiohttp 오버헤드 ~30ms)
tokens/s 대조:
- 2편 Warm Start: 98.6 tokens/s (직접 HTTP 클라이언트, 짧은 프롬프트)
- 3편 concurrent=1: 85~88 tokens/s (aiohttp 스트리밍, 긴 프롬프트)
- 차이 원인: 측정 도구(직접 HTTP vs aiohttp)와 프롬프트 길이(2문장 vs 3문장) 모두 다르므로 직접 비교는 제한적입니다. 두 값이 85~99 tokens/s 범위 내에 있다는 점에서 동일 모델·동일 환경임을 확인하는 참고 수준으로 해석하십시오.
아래 요약 테이블은 NUM_PARALLEL 값별 주요 성능 지표를 한눈에 비교합니다.
3. 프로덕션 동시 처리 최적화 가이드
3.1 OLLAMA_NUM_PARALLEL 설정 가이드
| 설정 | 적합 상황 | 메모리 추가 비용 |
|---|---|---|
1 (기본) | 단일 사용자, 최저 latency 우선 | 없음 |
2 | 소규모 서비스 (2-3명 동시 사용) | KV Cache × 1 추가 |
4 | 중규모 서비스, throughput 중시 | KV Cache × 3 추가 |
8+ | 대규모 서비스 (충분한 메모리 + GPU 필요) | KV Cache × 7+ 추가 |
⚠️ 주의: NUM_PARALLEL을 높이면 슬롯당 KV Cache가 추가 할당됩니다. llama3.2:3b (num_ctx=2048) 기준으로 NUM_PARALLEL=1일 때 메모리 ~5.8 GB, NUM_PARALLEL=2일 때 ~6.0 GB (+224 MB), NUM_PARALLEL=4일 때 ~6.5 GB (+672 MB)입니다. 대형 모델이나 긴 컨텍스트(num_ctx 8192+)에서는 슬롯당 수 GB가 추가될 수 있으므로, 반드시
ollama ps로 실제 메모리 점유를 확인한 뒤 설정하십시오.
권장 공식:
최대 NUM_PARALLEL = (가용 메모리 - 모델 메모리) / KV Cache per slot
llama3.2:3b 예시 (1편 실측 기반):
- 모델 메모리: ~5.8 GB
- 가용 메모리: 48 GB
- 이론상 최대: (48 - 5.8) / KV Cache ≈ 다수 슬롯 가능
- 실측 기반 권장: 2-4 슬롯 (throughput 수확 체감으로 4 이상 효과 미미)
num_ctx와 메모리 비용: 본 벤치마크는 num_ctx=2048 기준입니다. 컨텍스트 길이가 4배(8192)가 되면 슬롯당 KV Cache 비용도 약 4배(~896 MB)로 증가합니다. llama3.1(128k) 등 대형 컨텍스트 모델에서 NUM_PARALLEL을 높이면 슬롯당 수 GB가 추가되어 OOM 위험이 있으므로, KV Cache per slot은 1.2절의 공식으로 추정하거나
ollama ps로 메모리 증가분을 실측하는 것이 가장 정확합니다.
3.2 부하 분산 전략
| 전략 | 장점 | 단점 |
|---|---|---|
| 스케일업 (NUM_PARALLEL 증가) | 구성 간단, 모델 메모리 공유 | 수확 체감, 단일 장애점 |
| 스케일아웃 (멀티 인스턴스 + LB) | 선형 확장, 장애 격리 | 모델별 메모리 중복, 인프라 복잡 |
| 하이브리드 | 최적 균형 | 가장 복잡 |
권장: NUM_PARALLEL=2-4로 스케일업 후, 부하 초과 시 인스턴스 추가 (스케일아웃)
3.3 모니터링 지표
| 지표 | 임계값 | 의미 |
|---|---|---|
| Avg TTFT | > 2초 | 사용자 체감 지연 시작 |
| Max TTFT | > 5초 | 일부 사용자에게 심각한 지연 |
| Queue Wait | > 0ms | 슬롯 부족, NUM_PARALLEL 증가 검토 |
| Throughput 감소 | 이전 대비 20%+ 감소 | 시스템 과부하 |
# 현재 모델 상태 확인
curl -s http://localhost:11434/api/ps | python3 -c "
import sys, json
data = json.load(sys.stdin)
for m in data.get('models', []):
print(f\"{m['name']}: VRAM {m.get('size_vram',0)/1024/1024:.0f}MB\")
"
4. 마치며
핵심 정리
- NUM_PARALLEL은 throughput과 latency의 핵심 제어 변수. 기본값 1 (v0.17.4 기준)은 단일 사용자에만 적합
- 1→2 슬롯에서 throughput 35% 향상 (concurrent=4 기준, 80→108 tokens/s)이 가장 효과적. 4 이상에서는 메모리 대역폭 경합으로 수확 체감
- 슬롯 < 동시 요청 시 큐잉 발생, TTFT가 수 초~수십 초로 증가
- 최적 설정: 동시 사용자 수 ≤ NUM_PARALLEL을 유지하면 모든 요청이 큐잉 없이 즉시 처리
시리즈 전체 요약
| 주제 | 핵심 발견 | 핵심 해결책 |
|---|---|---|
| 1편 — 메모리 관리 | llama3.2:3b → 5.8GB RSS, num_ctx 2배 시 +224MB | 모델 크기/양자화 선택, MAX_LOADED_MODELS |
| 2편 — Cold Start | TTFT 881ms(Cold) vs 81ms(Warm), 10.8배 차이 | keep_alive 연장, 프리로드 + 헬스체크 |
| 3편 — 동시 처리 | NUM_PARALLEL 1→2: throughput 35%↑ (concurrent=4 기준), TTFT 663→114ms | NUM_PARALLEL=2 (소규모) ~ 4 (중규모), 초과 시 스케일아웃 |
이 세 가지 요소 — 메모리, Cold Start, 동시 처리 — 를 함께 최적화하면 Ollama를 프로덕션에서 안정적으로 운영할 수 있습니다.